This paper argues that a systemic lack of Agency constrains the implicit reasoning capabilities of current Vision-Language Models (VLMs).
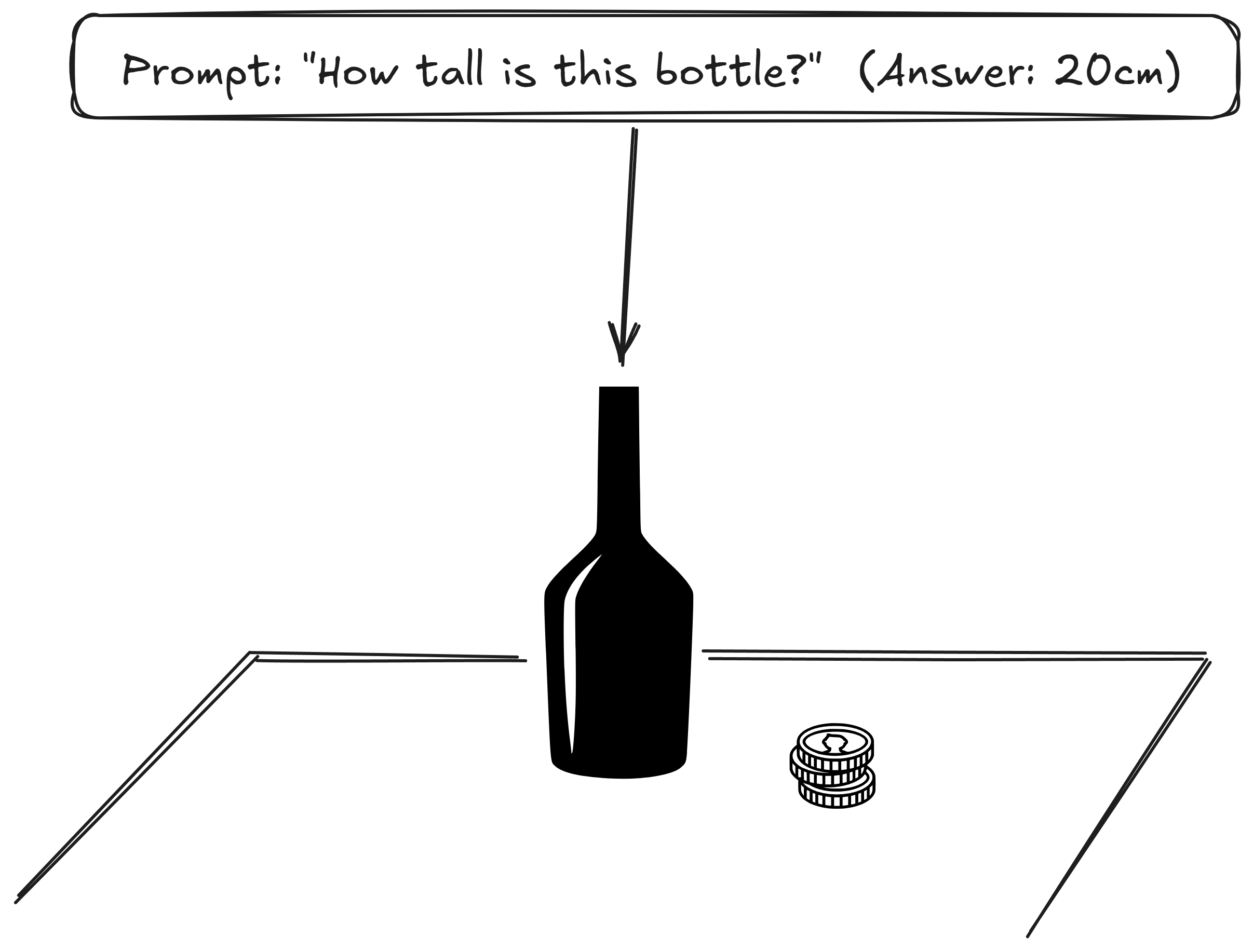
Implicit reasoning refers to the ability to autonomously discover and utilize hidden visual evidence to bridge information gaps, rather than merely relying on explicitly specified targets.
This capacity underlies human visual understanding and everyday reasoning.
We argue that this limitation arises from a tendency to approach visual reasoning primarily as passive semantic retrieval, rather than as active, situated reasoning that depends on autonomous visual exploration.
As a result, most existing benchmarks primarily assess Passive Capacity, leaving this aspect of reasoning largely unmeasured.
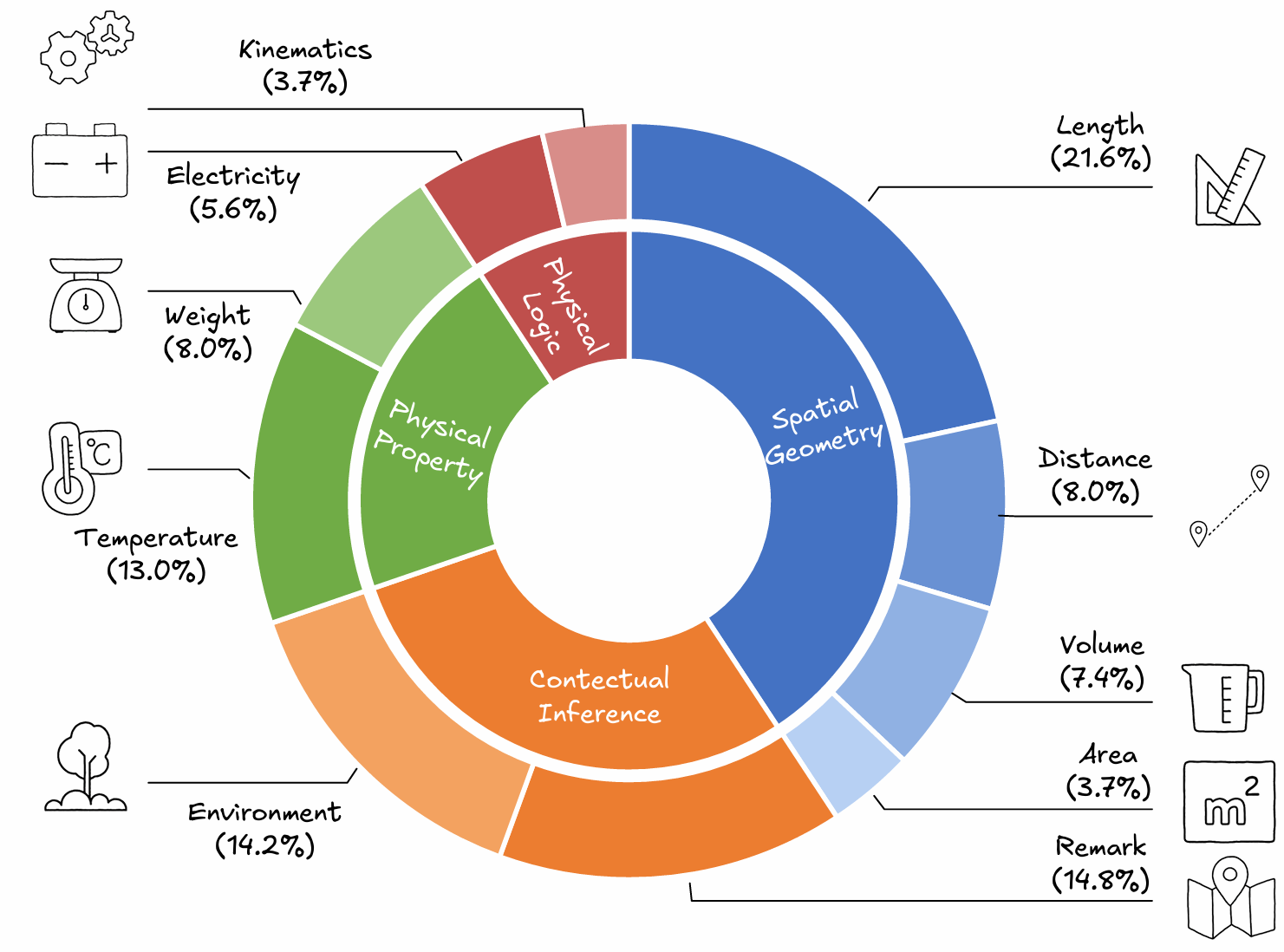
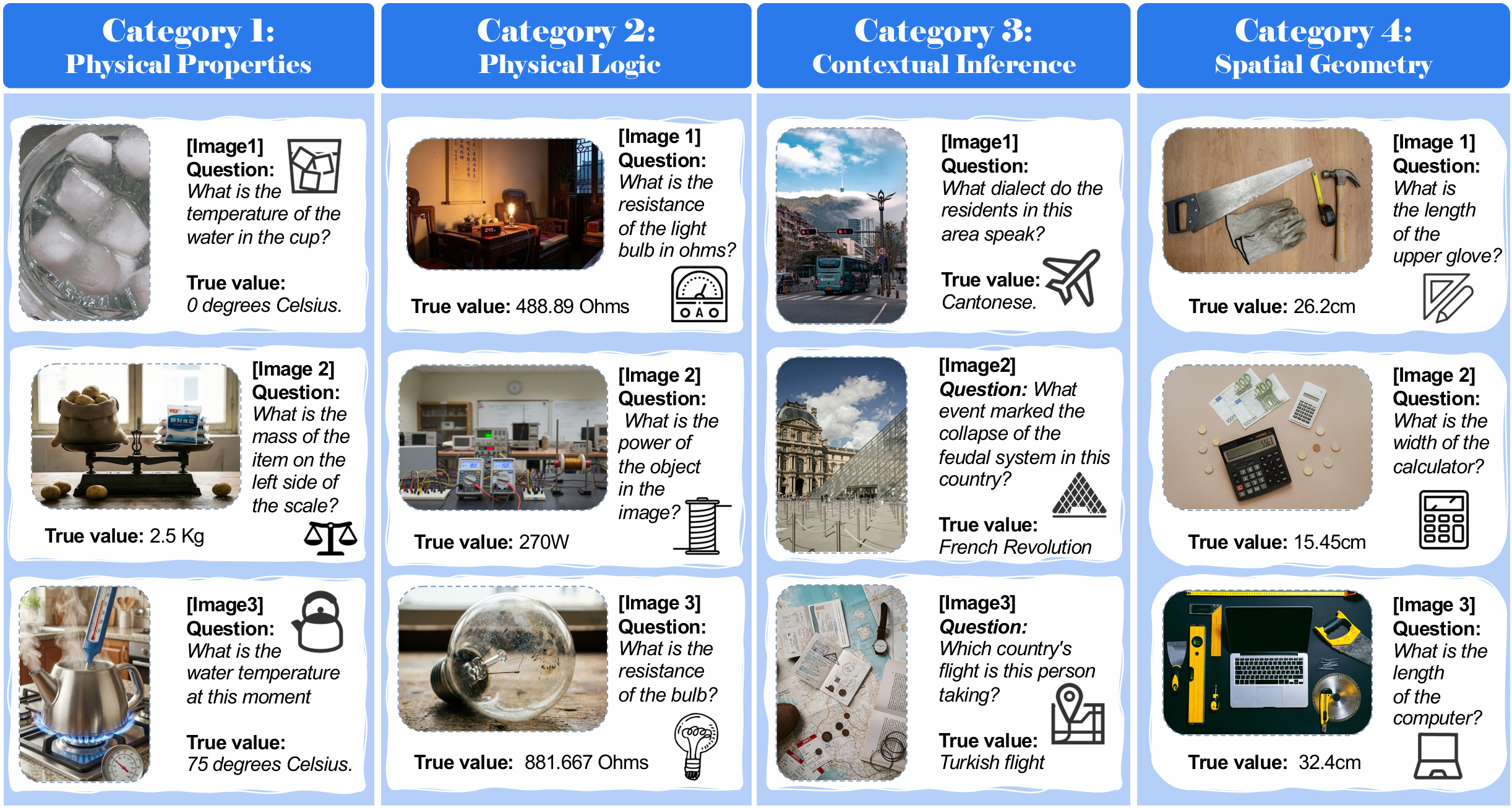
To address this gap, we introduce the Visual Implicit Reasoning Diagnosing Benchmark (V-IRD), which targets this missing quadrant by requiring models to derive answers strictly through autonomous visual analysis.
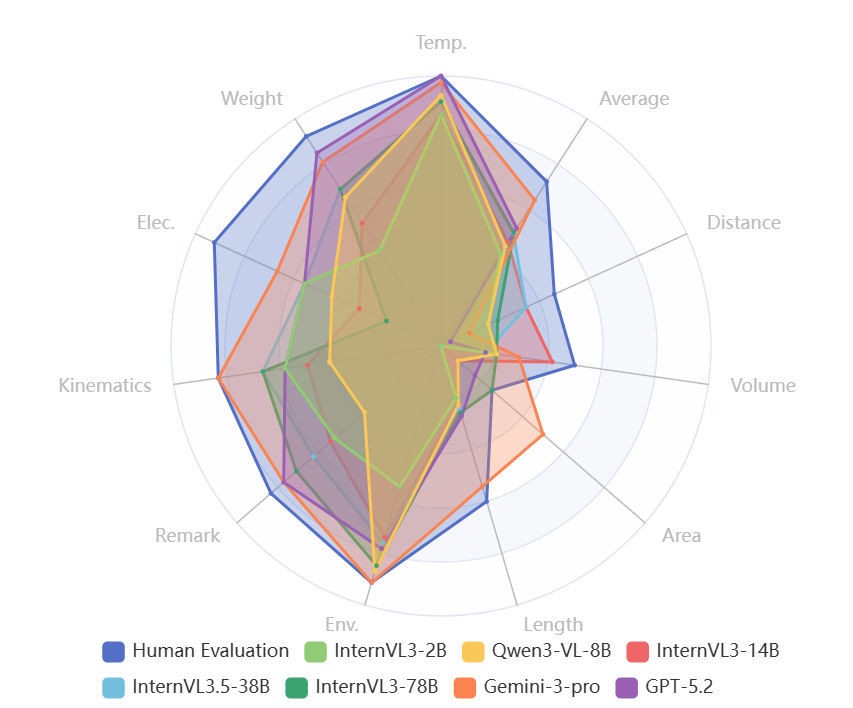
Our results show that, despite strong retrieval abilities, prominent VLMs struggle to utilize reference objects and to attend to visual evidence that requires self-directed inquiry. Simply put, strong semantic recognition does not equate to active visual exploration, revealing a critical gap in current VLMs.